How I Built a Company AI Assistant in 4 Days (Without Being an AI Expert)
I accidentally became a company’s AI guru and built an on-premise AI assistant in just four days, without being an AI expert. Here’s the hilarious, painful, espresso-fueled story of how it happened, what broke, what worked, and why hard things don’t get easier… but definitely get doable.
Hard Things Don't Get Easy, But They Get Doable
There's a line from Seneca I keep coming back to when I'm staring down something that looks impossible:
"It is not because things are difficult that we do not dare; it is because we do not dare that they are difficult." — Seneca, Epistulae Morales 104.26
This week I tested it!
The Day the CEO Declared War on AI (and Accidentally Drafted Me)
Just another busy corporate day.
You know the kind: Zoom meetings, mild chaos, and senior executives whose birth year is older than the wallpaper behind their honey-tone 1950s oak bookshelves.
For months now, the topic has been AI.
But was it the casual, "let's explore possibilities" type of AI topic.
Nope! It was the kind of;
“The end-is-near, competition-is-ahead, we-are-25-years-behind type of AI!”
They kept calling it "The AI problem."
I kept calling it a "you-don't-understand-AI" problem.
Let's be clear: this is not a tech company. It's a large, respected manufacturer, strong on craftsmanship, light on automation. They make impressive custom architectural products, and not Terminators.
So, while everyone else was dreaming of I, Robot–style factories, I quietly unmuted myself and offered the radical suggestion of… using AI to help write emails. Or edit documents. Or translate in our multilingual environment.
The Zoom window froze.
Not because of bandwidth congestion.
Because I had dragged them down from the "AI will rebuild the universe" cloud to "Let's check our grammar first."
One person contested loudly, "That's it? We use AI to check spelling mistakes?"
"Well," I said, "yes. Think of it like a helpful office assistant you asked for, who never complains."
Suddenly, everyone reset. The conversation went from apocalyptic sci-fi to: "Oh… that's… actually interesting and simple."
But then, because my universe loves comedy, the CEO leaned forward and said the words every IT person secretly fears:
"If it's that easy, why haven't we done it yet?"
Fair question.
Because sending corporate documents to random cloud AI systems is basically shouting your confidential pricing sheets out the window. The IT department knew this. They blocked everything. Rightfully so.
The CEO nodded vigorously: "Good. I don't want anyone uploading my cost sheet!"
Then the VP asked, "But how do other companies do it safely?"
That’s when I said, without sounding too hyperbolic here, that it ended up changing my fate or at the very least, this week’s priorities and date nite; "They use on-premise LLMs, their own internal AI."
The CEO lit up: "YES! I WANT THAT! OUR OWN AI! DO IT! NOW!"
And the room celebrated. AI was coming! The complex problem suddenly looked easy.
Well… for them.
Because the CEO wasn't yelling at the universe. He was shouting at me.
And I, brilliant ERP software developer and now blogger (cough cough on both fronts), but an AI systems architect? Yeah, no!
I was faced with these 2 choices;
- Politely decline and suggest an outside firm.
- Or lean into a decade of infrastructure & Dev experience and see if I could pull it off.
Guess which one my ego chose?
I promised a 7-day proof-of-concept.
This article is being written on Day 4.
And yes… the AI works.
Confession: I Didn't Start From Zero (And That's the Whole Point)
Here's something most "I built X in a weekend" stories conveniently skip:
I've been a developer for a while now.
I didn't learn AI from scratch in four days. I knew just enough of the AI ecosystem to wire existing tools together using skills I'd been building for years.
That distinction matters.
If someone with zero coding background attempted this, 50-60 hours of work wouldn't get them past "Hello World."
But if you've spent years shipping software? It's not easy, but it becomes achievable in a way it simply isn't for someone starting cold.
This isn't a story about hard things becoming easy. It's a story about how compounding skills let you tackle new hard things faster than you expect, but only because you've already paid the tuition on the foundational stuff.
What I Actually Had to Learn (AKA The Fun, Horrible Part)
For all you tech nerds, here's the brand-new stuff I had to Google at unhealthy speed:
- How to run LLMs locally.
- What RAG actually does (not the cleaning cloth).
- Why vector databases matter.
- GPU VRAM limitations.
- Tokenizers (the DMV of AI, nobody understands, but everyone needs).
- Why Llama 3 and Mistral are not zoo animals.
And here's the stuff I already knew that made it doable:
- Ubuntu networking (on a good day).
- Docker orchestration.
- REST APIs.
- Error logs.
- SQL indexing.
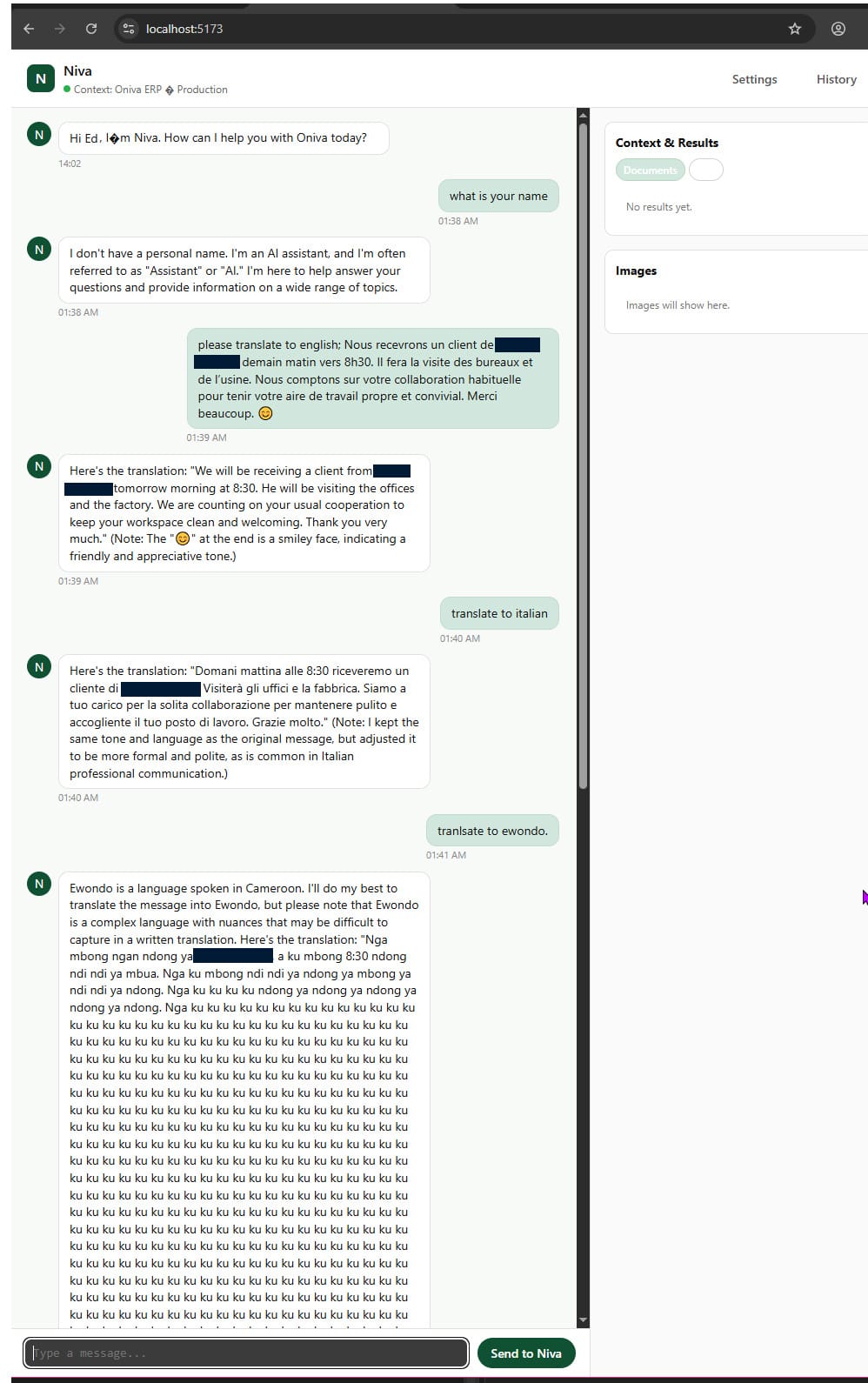
- How to calm down when nothing works and everything is on fire and the AI calls you "Ku! Ku!" (true story, see image)
That combination, old skill with new knowledge, is what made the impossible look merely horrifying instead of genuinely unachievable.
But let's be honest: I got lucky, too.
Fortunate that:
- Open-source LLMs existed and were mature enough to actually work.
- The CEO wanted something simple, to start with, not an AGI toaster.
- The immediate requirement didn't involve complex RAG pipelines or custom fine-tuning, which would've required another month of research.
None of that diminishes the work. But pretending those factors didn't matter would make this a dishonest story.
If you like deep dives into creative chaos, productivity under pressure, and nerdy lessons from real-life experiments, subscribe to get future posts delivered right to your inbox. Subscribe Now
How I Built "Niva" in Less Than 60 Hours
Day 1: Research and Setup.
Spent the first four hours just learning and figuring out which tools actually existed. Ollama, vLLM, Local AI. Installed Ubuntu Server on spare parts. Configured Docker and GPU drivers, which took way longer than it should have because, of course, it did.
Pulled my first LLM model (DeepSeek Coder, 6.7B parameters) and got it to respond to a test prompt at 11 PM. Nearly cried with relief.
Day 2: Backend Infrastructure.
Development of the C# API to handle chat requests and created LLM endpoints for completions, embeddings for ERP connections. Implemented conversation history and context management. Set up basic routing and error handling. The usual stuff.
Day 3: Frontend and Integration.
Built the chat interface using React. Added QOL functions like message threading, timestamps, and user context switching. Integrated some features for our multilingual environment and some ERP integration. Tested with real company documents. Spent too much time fixing some bugs that appeared when using real data, most likely due to some limitations.
Day 4: Polish and Documentation.
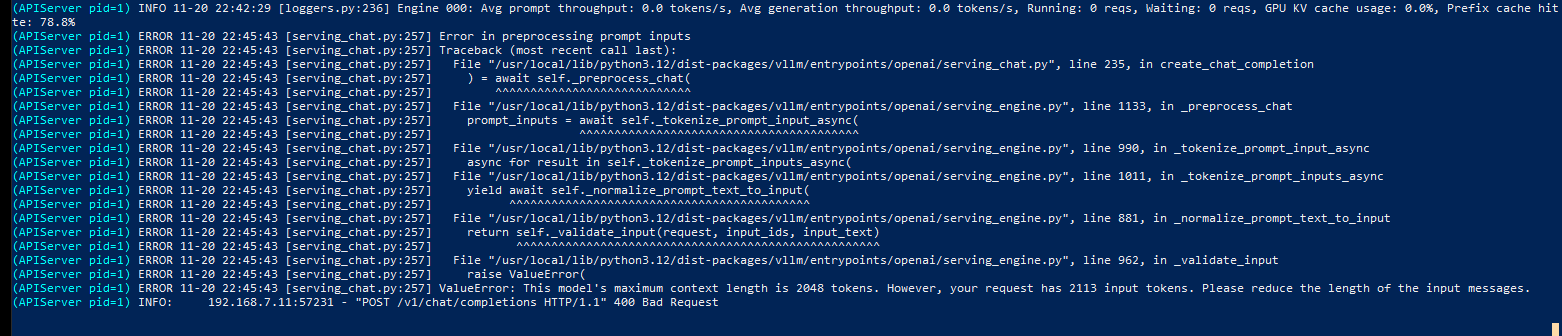
Cleaned up the UI. Added settings and history panels. Wrote basic presentation documentation for the team and prepared a demo for the CEO. Tested edge cases, like translating to Ewondo, which… worked surprisingly well? Until it hit a token limit while using a 4060 8GB GPU (Ouch).
Total: 50-60 hours of actual focused work.
Did I enjoy it? Every minute of it.
Did I suffer? Absolutely.
At one point, my wife asked if I was okay because I was laughing in that unhinged Jack Nicholson kind of way while staring at "Ku! Ku! Ku!" on my screen, as if the universe was trying to tell me something profound through sheer absurdity.
What Actually Happened Here
I would be lying if I said it was smooth sailing and stress-free. I worked nearly 60 hours in 4 days while keeping up with everything else. My eyes hurt. I survived on espresso and adrenaline.
The popular theme stating that "hard things are easy if you just break them down" is nonsense.
Breaking them down makes them doable, not easy.
There's a difference.
Every software API I'd ever built made this project easier to build. Every server I'd ever configured made this server faster to configure. Every bug I'd ever debugged gave me intuition for where to look when things broke.
But those skills transferred because this project was adjacent to what I already knew.
If the CEO had asked me to build a generative AI model from scratch or design a custom GPU kernel, I would be just as lost as anyone else.
I didn't build an LLM from scratch. I used Ollama to manage models, existing open-source LLMs trained by people much smarter than me, and standard Docker containers. Understanding which tools exist and which are off-the-shelf, production-ready saved me weeks, if not months, of work.
Even with experience, I broke this into tiny steps:
- Get the model to respond to anything
- Get it to respond correctly
- Get it to remember context
- Make the UI not look like trash
- Polish until demo-ready
Each small win gave me confidence that the next step was possible.
But here's what I can't know: what if I'd hit a wall at step 3? What if GPU memory limitations made context management impossible? What if the translation quality was unusably bad?
I got lucky that each subsequent step was actually achievable with the tools and time I had. Not every complex problem breaks down that cleanly.
Even though there is still lots to learn, four days ago, I had no idea how to deploy an LLM. Today, the company has its own AI assistant running locally, translating documents, and answering questions about internal data.
The gap between those two states wasn't magic. It was research, experimentation, failure, learning, and iteration, compressed into an absolutely brutal timeline because my ego wrote a check my body had to cash.
The Point
Hard things don't become easy. But they become doable once you break them down.
Use the right tools, acknowledge the skills you already have, accept that suffering is part of the process, and get a little lucky with timing and circumstances.
And honestly? That's enough.
Because once you get the smallest piece working, even badly, everything else becomes less terrifying.
Now, if you'll excuse me, I have a CEO demo to finalize, and Niva just started replying in Mandarin again.
Wish me luck.
Stay nerdy, stay nice… and break things responsibly.
Ed Nite
MindTheNerd.com
If you like deep dives into creative chaos, productivity under pressure, and nerdy lessons from real-life experiments, subscribe to get future posts delivered right to your inbox. Subscribe Now